
.svg "Snic_solutions-COLOR (2)")
When choosing between Data Virtualization vs Data Federation, the main question is which is better for your data integration needs; understanding that data virtualization includes various technique .
This article clarifies their differences and helps you decide.
Key Takeaways
-
Data virtu offers real-time access to data across diverse sources, enhancing analytics and organizational agility without the need for data replication.
-
Data federation integrates multiple data sources into a unified view without creating duplicates, simplifying data access and reducing storage costs.
-
Choosing between data virtu and data federation depends on the complexity of data sources, resource availability, and specific organization needs for efficient data integration.
Exploring Data Federation

Data federation is another powerful method for integrating data from multiple databases and data silos. Unlike data virtualization, which abstracts data access, data federation tools integrate various data sources into a single virtual database without creating duplicate copies. This approach allows organizations to unify data sources into a single source , presenting them as a cohesive whole, which can be accessed and queried efficiently.
One of the key advantages of data federation is that it requires no extra storage structure, making it an efficient solution to store data for data management. Additionally, data federation does not necessitate complex infrastructure or hardware tied to one particular data store , simplifying the implementation process.
However, organizations may face integration difficulties due to varying formats and incompatible systems, which can complicate data management.
How Data Federation Works
Data federation works by integrating data from various sources into a single format, allowing for unified access without creating duplicate copies. Each individual data store continues to operate autonomously and retains control by its respective divisions. A federated query engine takes a single query and transforms it into multiple subqueries, which are directed to the specific data sources for processing.

This means that data consumers can access federated data as though the underlying data stores are combined, simplifying interaction and data access. Implementing data federation may require system upgrades to ensure compatibility with existing data infrastructures, but the flexibility and efficiency it offers make it a compelling choice for many organizations.
Benefits of Data Federation
One of the primary benefits of data federation is the elimination of data silos, enabling easy sharing of data across different sources. This can significantly enhance business intelligence by providing a more comprehensive view of data from various sources, leading to better insights and decision-making.
Additionally, data federation reduces the costs associated with data storage by avoiding the need for extra physical infrastructure. The cost savings and improved data accessibility make data federation an attractive option for organizations looking to streamline their data management processes.
By enabling seamless data integration, data federation supports efficient data access and analysis, driving better business outcomes.
Comparing Data Virtualization and Data Federation
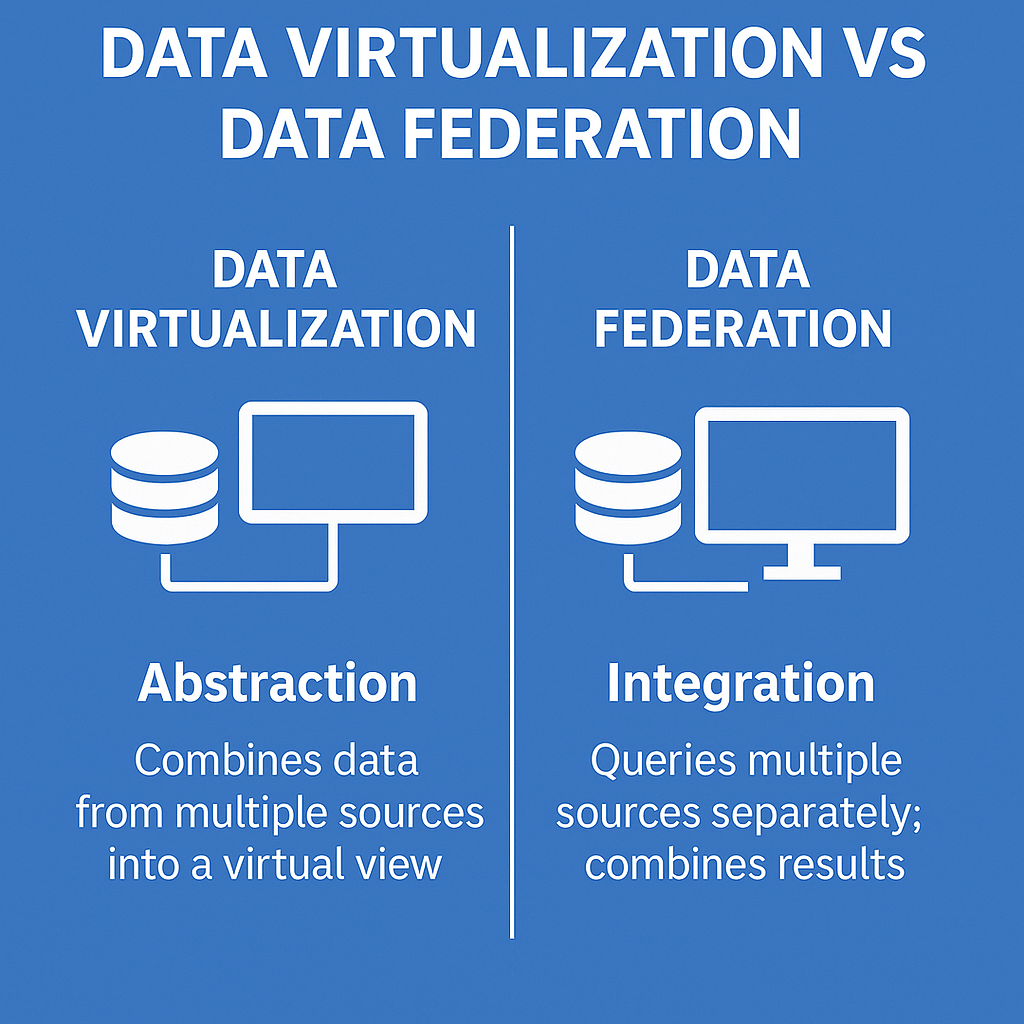
While both data virtualization and data federation aim to simplify data integration, they take different approaches to achieve this goal. Data virtualization creates a unified view without relocating data, whereas data federation integrates data by executing queries across sources. This fundamental difference impacts how each method handles data access across different systems nd management.
Data virtualization relies on real-time data access, which can lead to issues like data latency and inadequate bandwidth. In contrast, the data federation system may involve delays for processing queries but can result in significantly faster performance compared to traditional integration approaches.
Organizations often encounter data chaos and management difficulties when integrating most systems and disparate data sources that store data, highlighting the need for careful consideration of each approach’s strengths and weaknesses.
Integration Approach
Data virtualization utilizes a middleware layer to connect to source systems, establishing a virtual schema for querying. This approach provides a unified view of data without physically moving it, making it an efficient solution for integrating relational data stores and other data sources.
In contrast, data federation provides flexibility by executing user queries as subqueries that are sent to various data sources.
The choice between these integration approaches depends on the complexity and diversity of the data sources involved. If multiple data sources require different integration methods, data virtualization might be more beneficial. However, the presence of varied data formats and types can complicate data integration, necessitating a careful evaluation of the chosen approach.
Performance Considerations
Performance is a critical factor when comparing data virtualization and data federation. Data federation can result in significantly faster performance compared to traditional integration approaches. This is because data federation avoids the need for physically moving data, which can be time-consuming and resource-intensive.
On the other hand, optimized querying processes in data virtualization improve the efficiency of data retrieval across multiple sources in the same way. However, data virtualization may incur higher network bandwidth usage when accessing multiple systems due to its real-time access nature.
Therefore, organizations must weigh the performance benefits of each approach against their specific needs and infrastructure capabilities.
Implementation Challenges
Implementing data federation requires consistent system capability and adequate infrastructure capacity to function effectively. A common challenge is dealing with different SQL dialects across systems, which can complicate integration. Additionally, data federation faces challenges in scaling up due to query processing overhead that can impact performance. Furthermore, data federation requires more hardware resources due to the need for consolidating data from multiple sources, which can increase implementation costs and complexity.
Data virtualization may require more robust middleware capabilities to handle complex queries effectively. Understanding these implementation challenges is crucial for businesses to successfully integrate either approach into their data management strategy involving web services.
Factory Thread: A Smarter Way to Integrate Virtualization and Federation for Manufacturing
.svg)
When deciding between data virtualization and data federation, manufacturers often face a trade-off between real-time access and query efficiency. Factory Thread removes that compromise with a platform that seamlessly blends both paradigms—delivering high-performance integration across complex systems, with zero duplication.
Beyond Federation: True Real-Time Virtualization
Factory Thread is designed to virtualize data across ERP, MES, CRM, and quality systems—without relocating it. Unlike standard data federation tools that simulate unification via distributed queries, Factory Thread offers real-time, low-latency access to live data through a middleware layer tailored for high-speed industrial operations.
Connect, Query, Act—Faster
Using a visual workflow builder and natural language AI prompts, Factory Thread lets teams design, deploy, and iterate on data integrations with unprecedented speed. Whether you're synchronizing work orders from Siemens Opcenter or feeding real-time KPI dashboards, integrations are built in minutes—not weeks—with minimal technical effort.
Performance Meets Flexibility
Factory Thread’s architecture supports federated querying for legacy systems while optimizing virtualization for modern applications. This ensures both quick integration of new data sources and scalable performance across diverse data environments. It combines the best of both worlds: the agility of virtualization with the federation’s broad access capabilities.
Key Benefits for Manufacturers:
-
Unified Real-Time Data Layer: No more siloed systems—gain a complete view without moving data
-
Lower Operational Costs: Reduce infrastructure burden with no replication or heavy ETL processes
-
Enhanced Security and Governance: Centralized control over data access, even across hybrid and edge environments
-
AI-Driven Integration: Auto-generate workflows and mappings using business-friendly prompts
A Platform Built for Modern Data Integration
Factory Thread is more than just a tool—it’s a data integration fabric for smart manufacturing. By combining the strengths of virtualization and federation, it accelerates decision-making, enhances collaboration, and ensures data integrity—all while fitting seamlessly into your existing infrastructure.
For organizations balancing diverse data systems and demanding real-time insights, Factory Thread is the answer that traditional virtualization and federation tools alone can’t fully deliver.

Use Cases for Data Virtualization
Data virtualization is particularly effective in environments requiring quick access to diverse data sources without physical replication. Organizations use data virtualization to accelerate data access and streamline data management across diverse sources. This approach enables businesses to perform advanced analytics by integrating insights from multiple data stores seamlessly.
Employing data virtualization enables businesses to achieve improved agility and quicker decision-making through better data access. These use cases highlight the practical applications of data virtualization in enhancing organizational efficiency and analytics capabilities.
Real-Time Data Access
Data virtualization enables real-time access to data from different sources, allowing for immediate insights. Businesses can access and analyze data from multiple sources simultaneously, enhancing operational efficiency. This capability is crucial for sectors like finance, healthcare, and retail, where timely decisions are essential.
Centralizing data with data virtualization reduces silos and enables instant querying, providing organizations with current data regardless of location. This approach allows businesses to achieve immediate access to source data systems distributed across various systems, thus enhancing decision-making processes.
Enhanced Analytics
Data virtualization facilitates advanced analytics by integrating data from diverse sources into a unified view, streamlining the analysis process. This capability supports comprehensive analytics by aggregating data from multiple sources, providing a cohesive view that drives insights in a data warehouse.
Users can analyze and visualize source data from numerous sources in a cohesive manner, improving the depth of insights gained for the end user.
Use Cases for Data Federation

Data federation excels in creating data dashboards and enabling multi-source querying. It allows the combination of data from multiple sources without requiring physical integration, making the querying process seamless. Integrated data dashboards can provide comprehensive insights by leveraging federated data from various systems, showcasing a unified view of crucial metrics.
These use cases demonstrate how data federation can enhance data accessibility and analytical capabilities, supporting better decision-making.
Multi-Source Querying
Data federation facilitates querying across multiple data sources, allowing for a unified approach without physical integration. Federated data models allow businesses to run a single query across multiple databases simultaneously, streamlining data access. This capability enhances analytical capabilities and operational efficiency through quick access to centralized information.
Integrated Data Dashboards
Data federation enables the consolidation of data from various sources, creating dynamic dashboards that enhance analytical capabilities. Limited IT budgets may steer companies towards choosing data federation over virtualization, allowing for cost-effective dashboard development.
Integrated data dashboards allow for a comprehensive view of data from multiple sources, improving decision-making processes.
Choosing Between Data Virtualization and Data Federation
Choosing between data virtualization and data federation depends on the specific needs of the organization and the complexity of the data sources involved. Organizations that rely on highly complex and diverse data sources may find data virtualization more beneficial.
When determining the best approach, consider the specific needs of your data sources and how they will be accessed.
Assessing Data Complexity

Readiness for data federation is indicated when automated access to company databases can occur without needing a gatekeeper. However, the speed of the data federation system is dictated by the slowest data source that contributes to each federate query.
Assessing data complexity is crucial for determining the most suitable integration approach.
Evaluating Resource Availability
Organizations are increasingly adopting cloud-based data integration solutions to accommodate the dynamic nature of business environments and enhance scalability. The rising demand for cloud-based solutions is largely due to their ability to offer scalability, enhanced security, and cost-efficiency.
Evaluating resource availability is crucial for making informed decisions between data virtualization and data federation.
Common Challenges and Solutions
Data integration presents several challenges, including data quality issues and security concerns. Addressing these challenges is essential for successful implementation.
Data Quality Issues
Data accuracy requires rigorous cleansing processes to prevent errors in both data virtualization and federation. Regular data cleansing is essential to maintain high accuracy and reliability. Inconsistencies in data can arise from multiple sources, making data validation a critical step.
Data cleansing processes must be prioritized to rectify inaccuracies before data is utilized in analytics.
Security and Governance
Robust governance practices are essential to safeguard sensitive data against unauthorized access and breaches. Adopting data federation necessitates a comprehensive governance framework to manage data access and compliance effectively.
Robust security frameworks are essential to protect sensitive information in data virtualization and federation environments.
Future Trends in Data Integration
The landscape of data integration is continuously evolving, with emerging technologies focusing on seamless integration of diverse data sources to enhance accessibility and usability. The market for data virtualization is expected to grow significantly, reflecting the increasing need for efficient data integration from multiple sources. This growth is driven by businesses’ demands for real-time data access, enhanced analytics, and cost-effective data management solutions.
As organizations strive to stay competitive, adopting advanced data integration technologies will become increasingly important for business users. These technologies promise not only to improve data accessibility and usability but also to drive better business intelligence, data warehouses, and decision-making capabilities.
Cloud Integration
Cloud dynamics are reshaping data integration strategies, emphasizing the transition to cloud-based solutions. Future integrations in data management will increasingly rely on cloud capabilities to enhance accessibility and scalability. This shift allows businesses to transform your operations by combining data from various sources seamlessly, without the constraints of physical integration.
Cloud integration offers numerous benefits, including improved scalability, cost-efficiency, and enhanced security measures. These advantages make it an attractive option for organizations looking to modernize their data integration strategies.
Advanced Security Measures
Implementing synthetic data generation is gaining traction as a means to protect sensitive information while still allowing valuable insights to be derived from the data. The need for advanced security measures has become critical in protecting sensitive data within organizations.
Adopting advanced security measures ensures data protection and compliance, while also enabling robust data analysis and insights. This is particularly important as data integration technologies continue to evolve and become more sophisticated.
Frequently Asked Questions
What is the main difference between data virtualization and data federation?
The main difference between data virtualization and data federation is that data virtualization provides a unified view of data without moving it, while data federation integrates data by running queries across multiple sources.

Share this

Data Virtualization vs Data Warehouse: Essential Differences Explained

Data Virtualization vs Data Lake: Making the Right Choice for Your Business

No Comments Yet
Let us know what you think